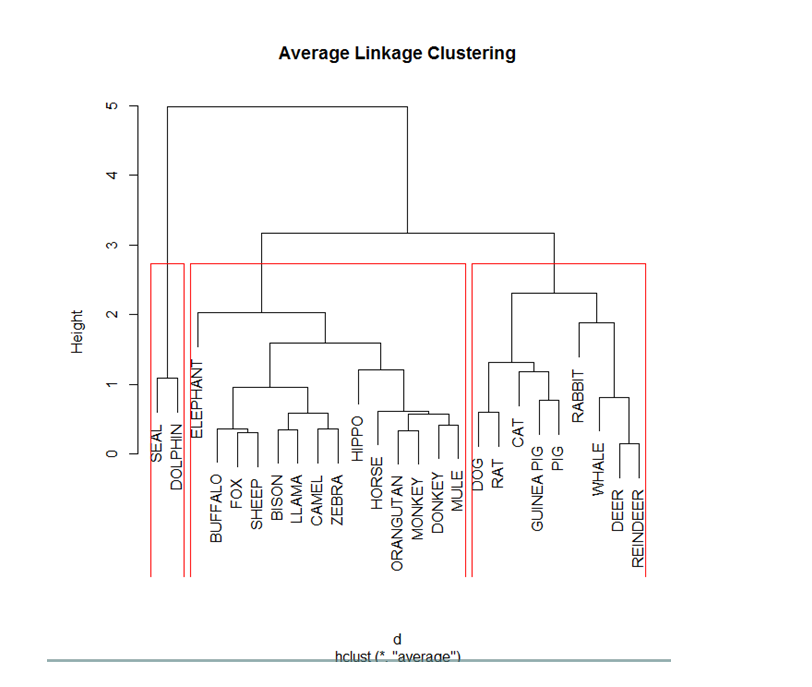
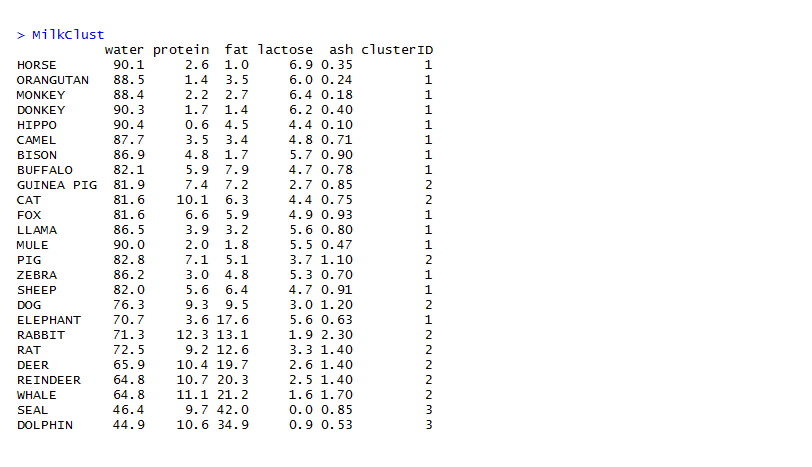
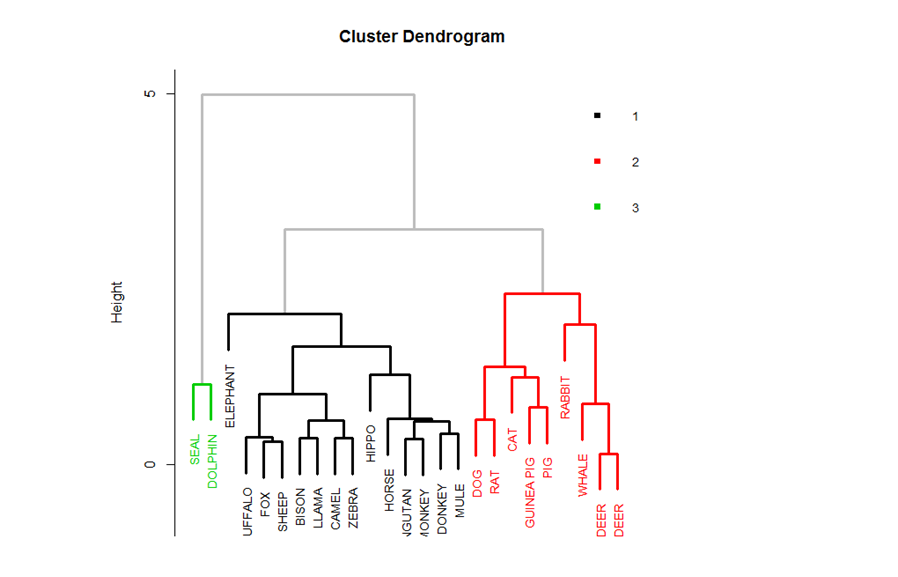
Big Data is no more a fleeting obsession. With numbers. It’s the beginning of a cognitive revolution that’s touching every facet of life and business on this planet.
Thanks to technological advancement, we’re churning more data than ever before. In fact, a lot more. And for good reason.
Every second we create new data – Don’t believe me?
Here are 10 mindboggling stats about big data – how it’s created, ways it’s being used and how much of it is still out there waiting to AMAZEEE us!!!
In short, this convinces us why we can’t afford to ignore big data and analytics:
Data volumes are exploding – the way it’s growing, by the end of 2020, it would generate 1.7 megabytes of new data every second for every human being living on this planet.
In a couple of years, our aggregated digital reservoir of data will expand from 4.4 zettabytes to approximately 44 zettabytes, or 44 trillion gigabytes.

Facebook users view 2.77 million videos and send 31.25 million messages, on an average every minute.
Whaaaat??!!!
Too much to process??
Wait, till you hear this!
Every minute up to 300 hours of video are being uploaded on YouTube, alone.

Yes, while you are reading this blog, loads of users are already uploading chunks of content online.

For that reason or other, within the next 5 years, there will be more than 50 billion smart connected devices in the world, all powered by cutting edge data analysis technology.
Be ready to collect, analyze and share data without batting eyelids.

By 2020, one third of total data will roll over to the cloud (a concentrated network of servers all connected through the Internet)

Distributed Computing is the future. Google uses it involving 1000 computers to solve a single search query within 0.2 seconds. Woah!!!

Hadoop market is expected to grow at a compound annual growth rate 58% beating $1 billion mark by 2020.
The White House is heard to have invested more than $200 million in big data projects.
Now, the most spectacular fact is that less than 0.5% of all data is analyzed and used till now… So, just imagine the potential it withholds!!
In the next five years, big data is going to touch the moon, and what about you?! Don’t you feel like joining the data-inspired bandwagon?

Go, grab a quick Big Data Hadoop training in Gurgaon — and fill in oodles of knowledge, skill and expertise for improving your career graph and business performance. For more information on big data hadoop certification, drop by our expert website of DexLab Analytics.
The blog has been sourced from —
https://www.datasciencecentral.com/profiles/blogs/15-astonishing-tweetable-facts-about-analytics
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.