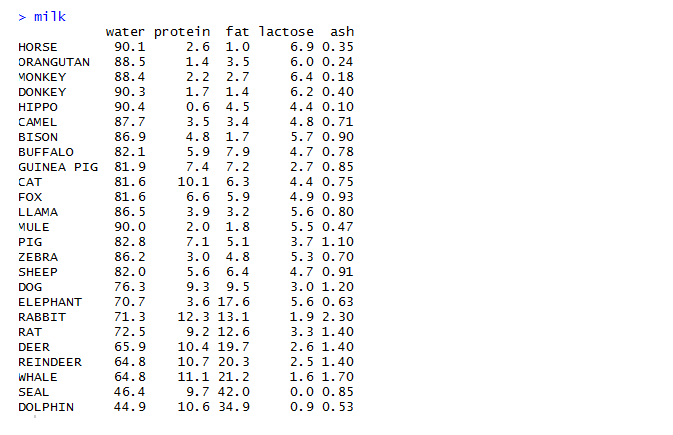
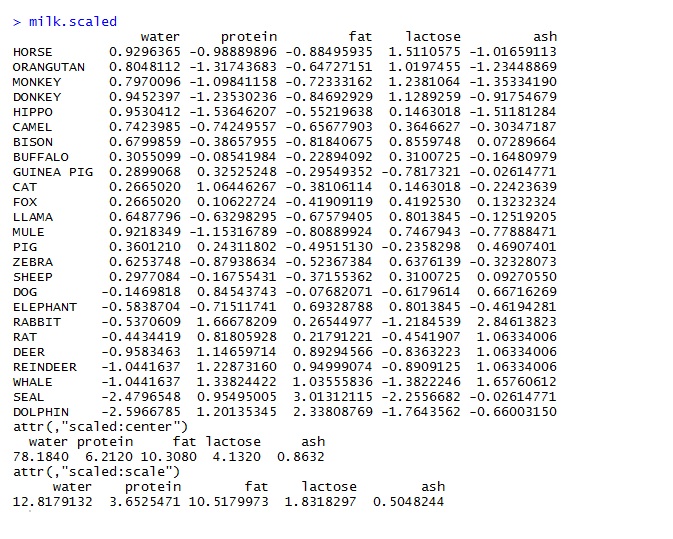
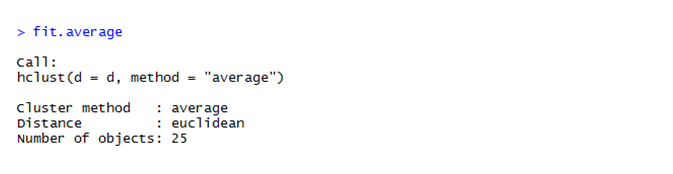
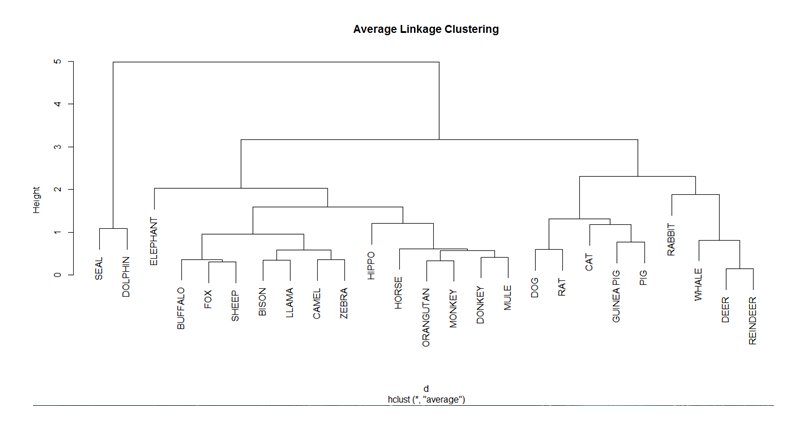
The World Economic Forum Annual Meeting 2018 was held in Davos, Switzerland. Here politicians, decision-makers from the world’s largest companies, and thought leaders come together to discuss about pressing global challenges. In this important platform, the opening words of historian, professors and famous author Yuval Harari were these— ‘’ we are probably the last generations of Homo sapiens.’’
He went on to explain that the new entities that humans will eventually evolve into will differ a lot more from the modern man than we did from our predecessors, the Neanderthals. However, the new species won’t be products of natural evolution of human genes, rather the result of humans engineering bodies and brains.

Harari said that in future, the power will lie in the hands of those who control data. Data is the most important asset in the world and has redefined the prerequisites of power and dominance. Earlier, the ownership of land and subsequently machinery separated humans into aristocrats and commoners, capitalists and workers. However, in the modern age data is the determining asset. This is reflected in the biggest companies of the world. Out of ten of the leading companies in the world, six are tech firms that deal with enormous amounts of data, namely Apple, Microsoft, Amazon, Alphabet, Tencent and Facebook. The fact that these companies are only around two decades old suggests the role big data played in their growth.
Technology has advanced to the extent that data can be used to hack not just computers but also human beings. It takes only two things- data and computing power. Computing power is advancing with enormous speed. Today, the processing powers of mobile phones we use are greater than the best computers from a few decades ago. At the same time, digital information is ever increasing. Humans generate an average of 2.5 million terabytes of data in a day!
The data humans generate is mostly in unstructured form, especially the data that comes from online surveys and social media platforms. However, if analyzed, this data can reveal a lot about the personality of the person generating the data. It is layered with meaning and very open to interpretation. Understandably, analysts are focusing more and more on making sense of this unstructured data.
Hacking the human mind with algorithms
Through machine learning, smart artificial intelligence and deep learning, it is now possible to mine volumes of data and find patterns that earlier went unnoticed to human minds, which are ‘biologically limited’. Right kind of data and the power of computers can be utilized to develop algorithms that know more about people than they do themselves. After all, humans are just biochemical algorithms and the amalgamation of neuroscience and artificial intelligence has enabled the creation of algorithms that help understand the mechanics of human mind better than ever before.
In the words of Harari— ‘’As you surf the internet, as you watch videos or check your social feed, the algorithms will be monitoring your eye movements, your blood pressure, your brain activity, and they will know.’’
To read more blogs on big data, analytics and all the latest trends in these fields, follow DexLab Analytics. We are a leading institute providing Hadoop training in Gurgaon. Do take a look at our big data Hadoop certifications— we are offering flat 10% discount in these courses.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.