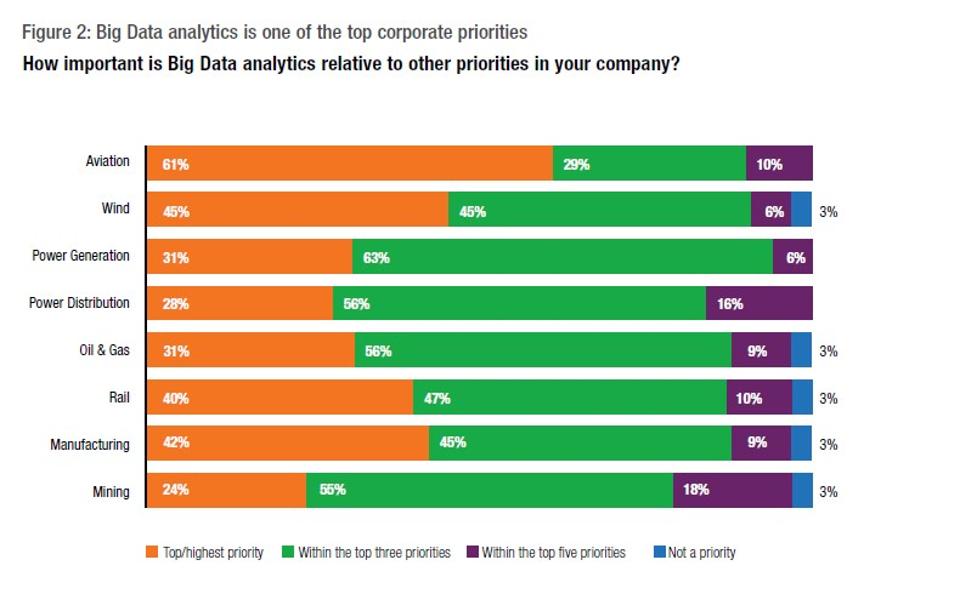
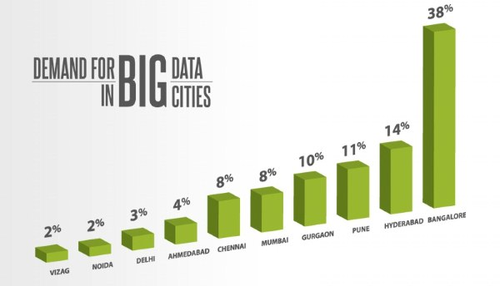
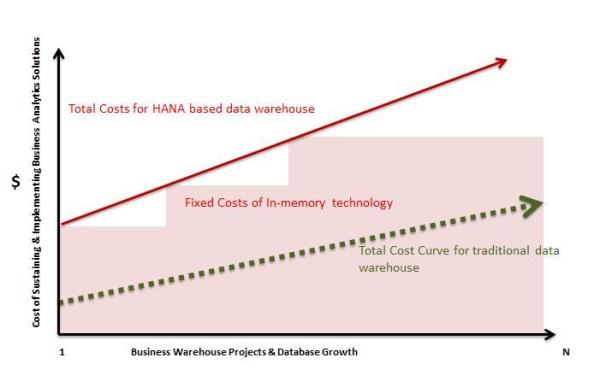
When Moore’s Law meets with modern day Business Intelligence, what happens? Disruption and then wider adoption!

With costs of implementing BI tools lowering, more and more enterprises are keen on jumping on-board the homebrewed variety of custom BI solution to help drive their business. The result of these efforts is that these days several organizations are pursuing data driven intelligent decision-making, at a cost, which is almost fractional compared to yesteryear’s Business Intelligence budgets.
A proper Big Data certification allows individuals to make the best of available smart BI solutions available out there!
But the question remains, as to are all these companies actually making better decisions?
Surely, most enterprises are now reaping the benefits of having a larger range of BI solutions available to them. Nevertheless, there is still a bigger room for error in the picture, which many firms tend to ignore.
If done right, BI solutions can deliver an ROI of USD 10.66 for the cost of every dollar spent on implementing them. But, as per a survey conducted by Gartner, the results are not so glorious for most firms. More than 70 percent of all BI implementations do not stand up to meet the business goals that were anticipated of them.
Due to the evolution and lowering BI solution prices, the demand for data analytics certification courses have grown by several manifolds.
Is there a secret formula to BI solution driven success? Well, starting with asking the right questions is always a good place to begin:
Here are six steps that can tip the balance in your favour:

Which data sources to use?
Do you know what the lifeblood is for BI? Why, data of course, data is what Business Intelligence strives upon. All firms do have a rudimentary strategy to collect and analyze data, however, they tend to overlook the data sources. The key here to note is – truly reliable data sources are the main difference between the success and failure of your Business Intelligence efforts.
These data sources do exist; all you have to do is choose right. In addition, the best thing about them is a lot of them are almost free of charge. Using the good ones will transform the way you look at your market, the business pipeline and the way you perceive your audience.
Are you warehousing your precious data right?
These are your firm’s single source data repositories. Warehouses store all the data you collect from various sources, and provide the same for when needed, on prompt for reporting and analysis. However, self-service BI tools can be a bit of hit-or-miss at times, where consistently handling data is a worry.
The key is to discover a data warehouse solution, which can efficiently store, curate and retrieve data for analysis on prompt.
Are your analytics solutions good enough?
Companies that are looking to use their own Business Intelligence infrastructures must identify the analytics architecture that best suits their necessities. However, unwieldy datasets in combination with a lack of processing maturity can dull the effort even before one decides to start!
How does your BI solution integrate with the existing platforms?
For incorporating enterprise-scale Business Intelligence solutions, it is necessary to have it work effortlessly with the different other information formats, processes and systems, which have already been established previously in the internal work pipeline.
So, the key here is to ask the question – will the necessary integration cost more in terms of resources and effort that you can afford?
Use reporting mechanisms that are both powerful as well as easy to understand:
The most persistent challenge in BI is to wrangle data, majority of users cannot understand any of it beyond a simplified visualization. Decision-makers may be fooled with the help of powerful visualization tools. However, the truth is that making it pretty alone will not get the job done right.
So, forget pretty, and ask the all important question of whether the reporting mechanism is useful in interpreting otherwise unintelligible data or not.
Has better compliance enabled through your Bi solutions?
If your BI solutions, directly impinges on relevant regulations (and so it will, when the time comes). Then the solutions should aid the compliance and not hinder it. A good BI solution should provide a means to trace and audit data and its sources wherever, needed.
In conclusion: the success of your efforts will ultimately depend on the data.
The field of data science is evolving in expertise. And even professionals involved in the field tend to vary in their capabilities and opinions about the same. So, the important thing is to consider the importance of data in your company, and that one has all the appropriate responses to the posed questions above.
You can learn to ask the right questions with comprehensive tableau BI training courses. For more information on tableau course details feel free to contact the experts at DexLab Analytics.
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.