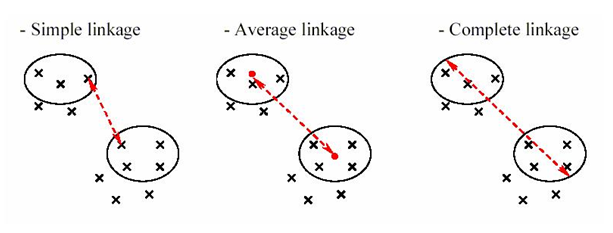
New data objects, like data planes, data streaming and data fabrics are gaining importance these days. However, let’s not forget the shiny data object from a few years back-Hadoop data lake architecture. Real-life Hadoop data lakes are the foundation around which many companies aim to develop better predictive analytics and sometimes even artificial intelligence.
This was the crux of discussions that took place in Hortonworks’ DataWorks Summit 2018. Here, bigwigs like Sudhir Menon shared the story behind every company wanting to use their data stores to enable digital transformation, as is the case in tech startups, like Airbnb and Uber.
In the story shared by Menon, vice president of enterprise information management at hotelier Hilton Worldwide, Hadoop data lake architecture plays a key role. He said that all the information available in different formats across different channels is being integrated into the data lake.
The Hadoop data lake architecture forms the core of a would-be consumer application that enables Hilton Honors program guests to check into their rooms directly.
A time-taking procedure:
Menon stated that the Hadoop data lake project, which began around two years back, is progressing rapidly and will start functioning soon. However, it is a ‘’multiyear project’’. The project aims to buildout the Hadoop-based Hotonworks Data Platform (HDP) into a fresh warehouse for enterprise data in a step-by-step manner.
The system makes use of a number of advanced tools, including WSO2 API management, Talend integration and Amazon Redshift cloud data warehouse software. It also employs microservices architecture to transform an assortment of ingested data into JSON events. These transformations are the primary steps in the process of refining the data. The experience of data lake users shows that the data needs to be organized immediately so that business analysts can work with the data on BI tools.
This project also provides a platform for smarter data reporting on the daily. Hilton has replaced 380 dashboards with 40 compact dashboards.
For companies like Hilton that have years of legacy data, shifting to Hadoop data lake architectures can take a good deal of effort.
Another data lake project is in progress at United Airlines, a Chicago-based airline. Their senior manager for big data analytics, Joe Olson spoke about the move to adopt a fresh big data analytics environment that incorporates data lake and a ‘’curated layer of data.’’ Then again, he also pointed out that the process of handling large data needs to be more efficient. A lot of work is required to connect Teradata data analytics warehouse with Hortonworks’ platform.
Difference in file sizes in Hadoop data lakes and single-client implementations may lead to problems related to garbage collection and can hamper the performance.
Despite these implementation problems, the Hadoop platform has fueled various advances in analytics. This has been brought about by the evolution of Verizon Wireless that can now handle bigger and diverse data sets.

In fact, companies now want the data lake platforms to encompass more than Hadoop. The future systems will be ‘’hybrids of on-premises and public cloud systems and, eventually, will be on multiple clouds,’’ said Doug Henschen, an analyst at Constellation Research.
Large companies are very much dependent on Hadoop for efficiently managing their data. Understandably, the job prospects in this field are also multiplying.
Are you a big data aspirant? Then you must enroll for big data Hadoop training in Gurgaon. At Dexlab industry-experts guide you through theoretical as well as practical knowledge on the subject. To help your endeavors, we have started a new admission drive #BigDataIngestion. All students get a flat discount on big data Hadoop certification courses. To know more, visit our website.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.