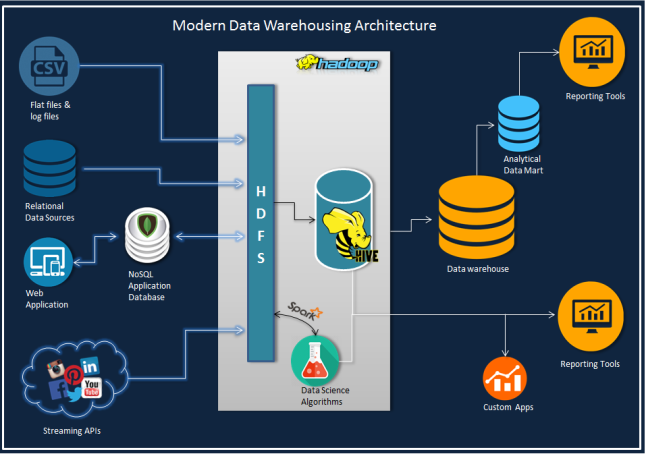
The world of hadoop data tooling is flourishing. It’s being said, Hadoop is shifting from possible data warehousing to an accomplished big data analytics set-up.
Back in the day, right after Hadoop at Yahoo was first invented, proponents of big data asserted its potential for substituting enterprise data warehouses, framed on business intelligence.
Open source Hadoop data tooling became a preferred choice more as an alternative to those insanely expensive existing systems – as a result, over time, the focus shifted to expanding existing data warehouses and more. Intricate Hadoop applications today are known as data lakes and of late big data tooling is found swelling beyond meager data warehouses.
“We are seeing increasing capabilities on the Hadoop and open source side to take over more and more of the corporation’s data and workloads, including BI,” said Mike Matchett, an analyst and founder of the Small World Big Data consultancy.

Self Service and Big Data
In August, Cloudera launched Workload XM management services designed exclusively for cloud-based analytics. Alternatively, the company built a hybrid Cloudera Data Warehouse and a Cloudera Altus Data Warehouse, capable of running over both Microsoft Azure clouds and AWS.
The main objective of management services is to bring forth some visibility into various data workloads. Workload XM is constructed to aid administrators in presenting reliable service-level agreements for self-service analytics applications – says Anupam Singh, GM of Analytics at Cloudera, Palo Alto, Calif.
Importantly, Singh also mentioned that the cloud warehouse offers encryption for data both at still and in motion, and provides a better view into the trajectory of data sets in analytics workloads. Such potentials have gained momentum and recognition as well as GDPR and other programs.
However, all these discussions boil down to one point, which is how to increase the use of big data analytics. “Customers don’t look at buzzwords like Hadoop and cloud. But they do want more business units to access the data,” he added.
Data on the Wheels
Hadoop player, Hortonworks is a Cloud aficionado. In June, the company broadened its Google Cloud existence with Google Cloud Storage support. Enhancing real-time data analytics and management is a priority.
Meanwhile, in August, Hortonworks churned out Streams Messaging Manager (SMM) with an objective of handling data streaming and provide administrators comprehensive views into Kafka messaging clusters. They have increasingly become popular amongst big data pipelines.
These management tools are crucial for moving Hadoop-inspired big data analytics into production capacities, where in data warehouses fails performing – thus, recommendation engines and fraud detection appears to be a saving grace!
Meanwhile, Kafka-related capabilities in SMM are going on getting advanced and with recently released Hortonworks DataFlow 3.2, the performance for data streaming amplified.
R Adaptability
Similar to its competitors, MapR has bolstered its capabilities beyond its original scope of being used as a mere data warehouse replacement. Early this year, the organizers released a new version of its MapR Data Platform equipped with better streaming data analytics and new item data services that would easily work on cloud as well as premises.
As final thoughts, the horizon of Hadoop is expanding, while data tooling keeps modifying. However, today, unlike before, Hadoop is not only the sole choice for doing data analytics – the choice includes Apache Spark and Machine Learning. All being extremely superior and effective when put to use.
If you are looking for Apache Spark Certification, drop by DexLab Analytics. Their Apache Spark Training program is extremely well-crafted and in sync with industry demands. For more, visit the site.
The article has been sourced from — searchdatamanagement.techtarget.com/news/252448331/Big-data-tooling-rolls-with-the-changing-seas-of-analytics
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.