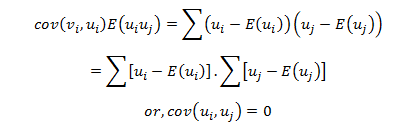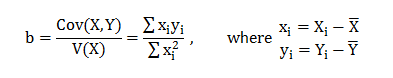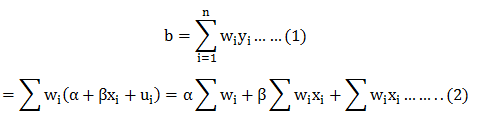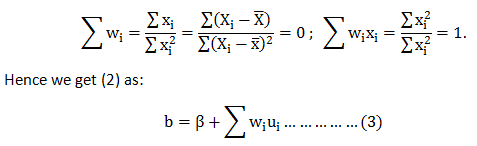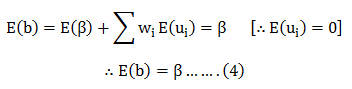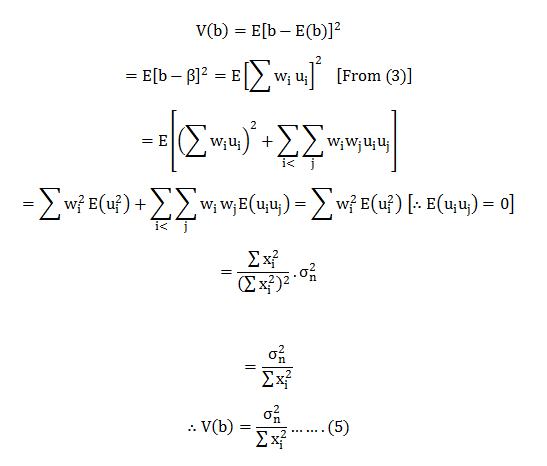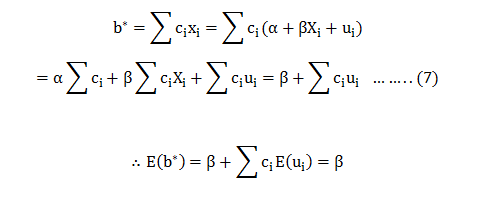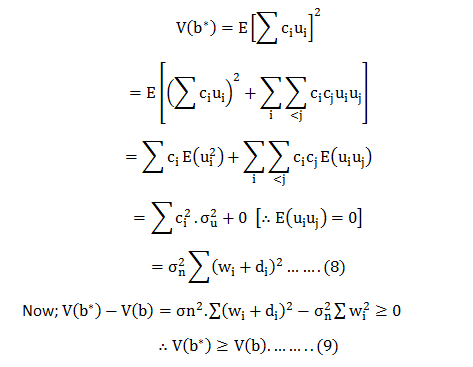The most common question we come across in DexLab Analytics HQ is how to take a step into the world of analytics and data science. Of course, grabbing a data science job isn’t easy, especially when there is so much hype going around. This is why we have put together top 5 ways to bag the hottest job in town. Follow these points and swerve towards your dream career.

Enhance Your Skills
At present, LinkedIn in the US alone have 24,697 vacant data scientist positions. Python, SQL and R are the most common skills in demand followed by Tensorflow, Jupyter Notebooks and AWS. Gaining statistical literacy is the best way to grab these hot positions but for that, you need hands-on training from an expert institute.
If interested, you can check out analytics courses in Delhi NCR delivered by DexLab Analytics. They can help you stay ahead of the curve.
Create an Interesting Portfolio
A portfolio filled with machine learning projects is the best bet. Companies look for candidates who have prior work experience or are involved in data science projects. Your portfolio is the potential proof that you are capable enough to be hired. Thus, make it as attractive as possible.
Include projects that qualify you to be a successful data scientist. We would recommend including a programming language of your choice, your data visualization skill and your ability to employ SQL.
Get Yourself a Website
Want to standout from the rest? Build up your website, create a strong online presence and continuously add and update your Kaggle and GitHub profile to exhibit your skills and command over the language. Profile showcasing is of utmost importance to get recognized by the recruiters. A strong online presence will not only help you fetch the best jobs but also garner the attention of the leads of various freelance projects.
Be Confident and Apply for Jobs You Are Interested In
It doesn’t matter if you possess the skills or meet the job requirements mentioned on the post, don’t stop applying for the jobs that interest you. You might not know every skill given on a job description. Follow a general rule, if you qualify even half of the skills, you should apply.
However, while job hunting, make sure you contact recruiters, well-versed in data science and boost your networking skills. We would recommend you visit career fairs, approach family, friends or colleagues and scroll through company websites. These are the best ways to look for data science jobs.

Improve Your Communication Skills
One of the key skills of data scientists is to communicate insights to different users and stakeholders. Since data science projects run across numerous teams and insights are often shared across a large domain, hence superior communication skill is an absolute must-have.
Want more information on how to become a data scientist? Follow DexLab Analytics. We are a leading data analyst training institute in Delhi offering in-demand skill training courses at affordable prices.
The blog has been sourced from ― www.forbes.com/sites/louiscolumbus/2019/04/14/how-to-get-your-data-scientist-career-started/#67fdbc0e7e5c
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.