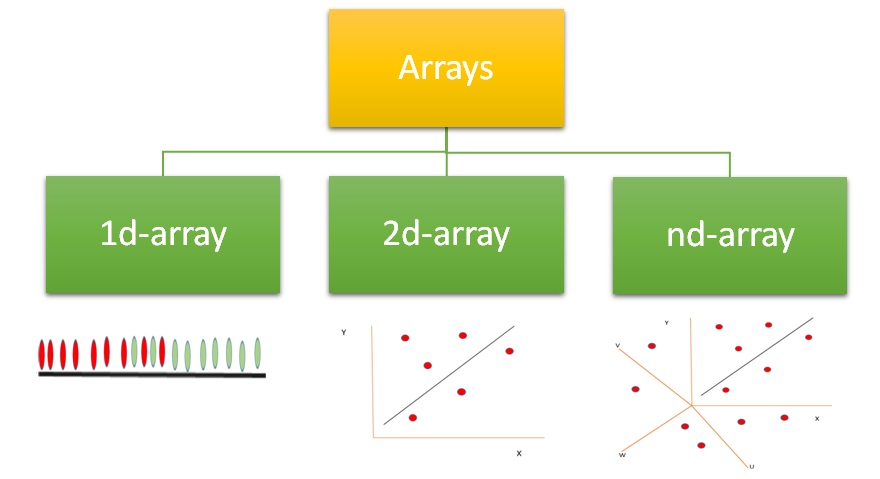
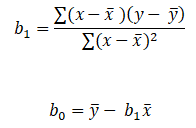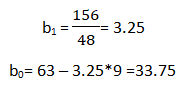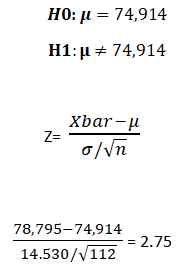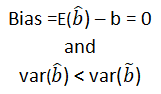NumPy also known as numerical python, is a library consisting of multidimensional array objects and a collection of routines for processing those arrays. Using NumPy, mathematical and logical operations on arrays can be performed without it which was not possible. For example-
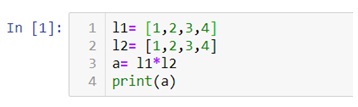
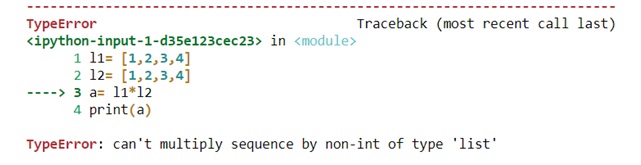
Multiplication of two lists will cause an error as a data structure like lists, tuple, dictionaries and sets do not allow mathematical operations.
Therefore we need NumPy to covert our data structures like lists into 1d, 2d, 3d or nd arrays so that mathematical operations can be performed. U
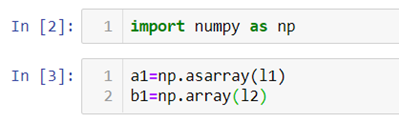
We can use .array() methods to create these arrays.
Now let’s check out few examples and also perform few mathematical operations to have a better understanding.
In the above code we first import NumPy library and then use .array() method to two 1d-array a1 and b1 using the list we previously created.
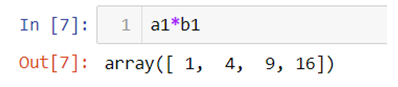
Now let’s multiply a1 and b1 array.
Now let’s use .array() method to directly create an array.
Arrays can be created using lists, tuples and dictionaries as you can see in the above example.
Now for 2-d arrays recall that we can also make list of lists. Let’s use that to create 2d-arrays.
2d-arrays can also be created using tuples.
Remember that we are not using these as matrices because matrix multiplication is an entirely different thing we are just trying to perform mathematical operations which were otherwise not possible.
Random Module
Numpy also has various ways with which we can create array of random numbers which then can be used in number of ways like generating a data for practice purposes or for building beautiful graphs for a presentation.
Given below is a list of type of random numbers you can generate
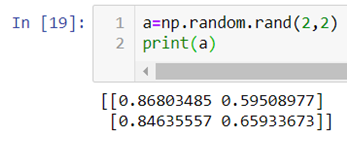
.rand() :- This particular method helps you generate uniformly distributed random numbers i.e. numbers between 0 and 1 where each number between 0 and 1 will have equal probability to be in the sample dataset.
The above code generates a 2d-array with values between 0 and 1.
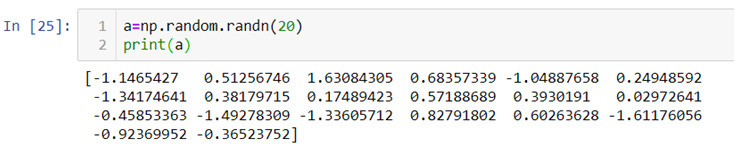
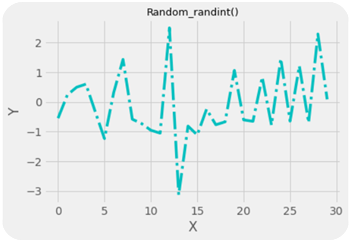
.randn():- This method generates normally distributed random numbers i.e. numbers between -3 and +3 where mean=median=mode and ploted gives a bell shaped curve.
Here the 20 random numbers are generated ranging between -3 and + 3.
Note:- Remember that the data is randomly picked from the normally distributed values between -3 and +3 so the graph is not bell shaped but the original data from which the values are being picked randomly is bell shaped with mean=median-mode.
.randint():-This method generates random integers between a given range.
So, with that we come to the end of the discussion on the Numpy. Hopefully it helped you understand Numpy, for more information you can also watch the video tutorial attached down this blog. DexLab Analytics offers machine learning courses in delhi. To keep on learning more, follow DexLab Analytics blog.
In our previous blog we studied about the basic concepts of Linear Regression and its assumptions and let’s practically try to understand how it works.
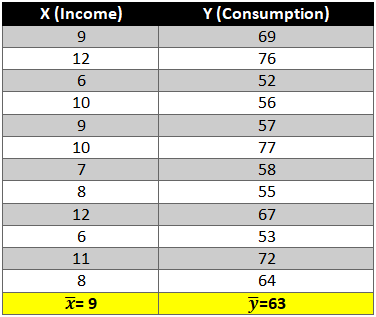
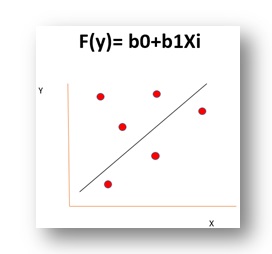
Given below is a dataset for which we will try to generate a linear function i.e.
y=b0+b1Xi
Where,
y= Dependent variable
Xi= Independent variable
b0 = Intercept (coefficient)
b1 = Slope (coefficient)
To find out beta (b0& b1) coefficients we use the following formula:-
Let’s start the calculation stepwise.
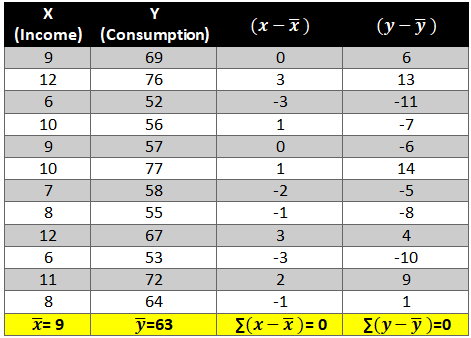
First let’s find the mean of x and y and then find out the difference between the mean values and the Xi and Yie. (x-x ̅ ) and (y-y ̅ ).
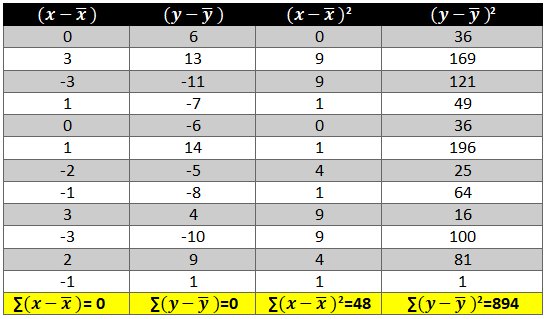
Now calculate the value of (x-x ̅ )2 and (y-y ̅ )2. The variation is squared to remove the negative signs otherwise the summation of the column will be 0.
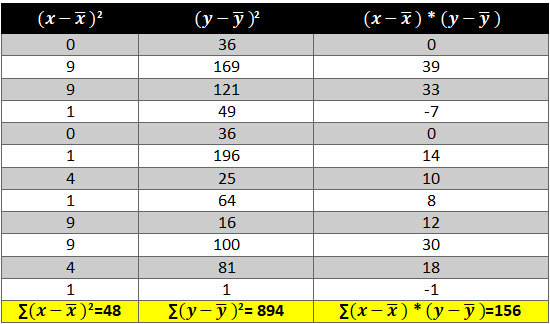
Next we need to see how income and consumption simultaneously variate i.e. (x-x ̅ )* (y-y ̅ )
Now all there is left is to use the above calculated values in the formula:-
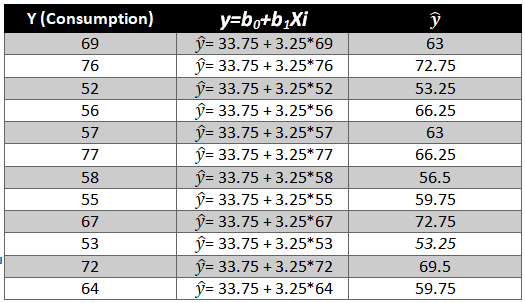
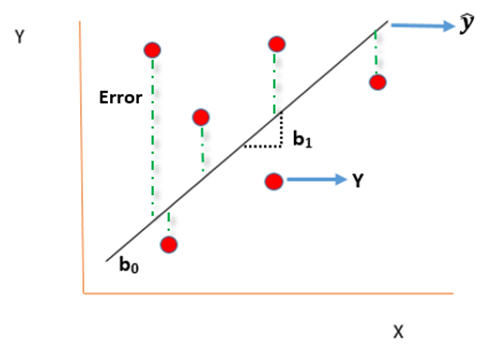
As we have the value of beta coefficients we will be able to find the y ̂(dependent variable) value.
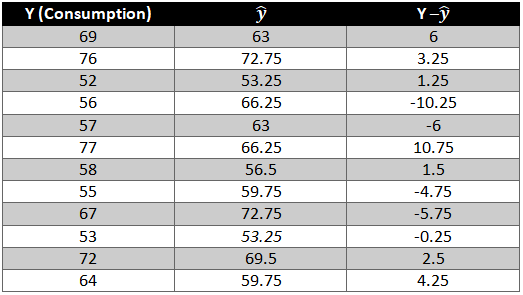
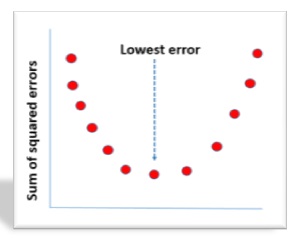
We need to now find the difference between the predicted y ̂ and observed y which is also called the error term or the error.
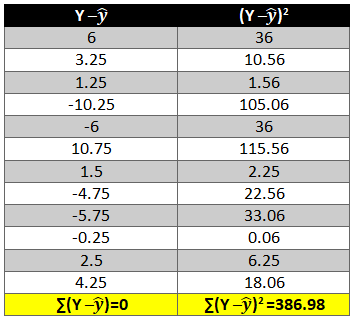
To remove the negative sign lets square the residual.
What is R2 and adjusted R2 ?
R2 also known as goodness of fit is the ratio of the difference between observed y and predicted and the observed y and the mean value of y.
Hopefully, now you have understood how to solve a Linear Regression problem and would apply what you have learned in this blog. You can also follow the video tutorial attached down the blog. You can expect more such informative posts if you keep on following the DexLab Analytics blog. DexLab Analytics provides data Science certification courses in gurgaon.
Artificial Intelligence, or, its more popular acronym AI is no longer a term to be read about in a sci-fi book, it is a reality that is reshaping the world by introducing us to virtual assistants, helping us be more secure by enabling us with futuristic measures. The evolution of AI has been pretty consistent and as we are busy navigating through a pandemic-ridden path towards the future, adapting to the “new normal”, and becoming increasingly reliant on technology, AI assumes a greater significance.
The AI applications which are already being implemented has resulted in a big shift, causing an apprehension that the adoption of AI technology on a larger scale would eventually lead to job cuts, whereas in reality, it would lead to the creation of new jobs across industries. Adoption of AI technology would push the demand for a workforce that is highly skilled, enrolling in an artificial intelligence course in delhi could be a timely decision.
Now that we are about to reach the end of 2020, let us take a look at the possible impacts of AI in the future.
AI will create more jobs
Yes, contrary to the popular apprehension AI would end up creating jobs in the future. However, the adoption of AI to automate tasks means yes, there would be a shift, and a job that does not need special skills will be handled by AI powered tools. Jobs that could be done without error, completed faster, with a higher level of efficiency, in short better than humans could be performed by robots. However, with that being said there would be more specialized job roles, remember AI technology is about the simulation of human intelligence, it is not the intelligence, so there would be humans in charge of carrying out the AI operated areas to monitor the work. Not just that but for developing smarter AI application and implementation there should be a skilled workforce ready, a report by World Economic Forum is indicative of that. From design to maintenance, AI specialists would be in high demand especially the developers. The fourth industrial revolution is here, industries are gearing up to build AI infrastructure, it is time to smell the coffee as by the end of 2022 there will be millions of AI jobs waiting for the right candidates.
Dangerous jobs will be handled by robots
In the future, hazardous works will be handled by robots. Now the robots are already being employed to handle heavy lifting tasks, along with handling the mundane ones that require only repetition and manual labor. Along with automating these tasks, the robot workforce can also handle the situation where human workers might sustain grave injuries. If you have been aware and interested then you already heard about the “SmokeBot”. In the future, it might be the robots who will enter the flaming buildings for assessment before their human counterparts can start their task. Manufacturing plants that deal with toxic elements need robot workers, as humans run a bigger risk when they are exposed to such chemicals. Furthermore, the nuclear plants might have a robot crew that could efficiently handle such tasks. Other areas like pipeline exploration, bomb defusing, conducting rescue operations in hostile terrain should be handled by AI robots.
Smarter healthcare facilities
AI implementation which has already begun would continue to transform the healthcare services. With AI being in place CT scan and MRI images could be more precise pointing out even minuscule changes that earlier went undetected. Drug development could also be another area that would see vast improvement and in a post-pandemic world, people would need to be better prepared to fight against such viruses. Real-time detection could prevent many health issues going severe and keeping a track of the health records preventive measures could be taken. One of the most crucial changes that could be revolutionary, is the personalized medication which could only be driven by AI technology. This would completely change the way healthcare functions. Now that we are seeing chat bots for handling sales queries, the future healthcare landscape might be ruled by virtual assistants specifically developed for offering assistance to the patients. There are going to be revolutionary changes in this field in the future, thereby pushing the demand for professionals skilled in deep learning for computer vision with python.
Smarter finance
We are already living in an age where we have robo advisors, this is just the beginning and the growing AI implementation would enable an even smarter analytics system that would minimize the credit risk and would allow banks and other financial institutes to minimize the risk of fraud. Smarter asset management, enhanced customer support are going to be the core features. Smarter ML algorithms would detect any and every oddity in behavior or in transactions and would help prevent any kind of fraud from happening. With analytics being in place it would be easier to predict the future trends and thereby being more efficient in servicing the customers. The introduction of personalized services is going to be another key feature to look out for.
Retail space gets a boost
The retailers are now aiming to implement AI applications to offer smart shopping solutions to the future buyers. Along with coming up with personalized shopping suggestions for the customers and showing them suggestions based on their shopping pattern, the retailers would also be using the AI to predict the future trends and work accordingly. Not just that but they can easily maintain the supply and demand balance with the help of AI solutions and stock up items that are going to be in demand instead of items that would not be trendy. The smarter assistants would ensure that the customer queries are being handled and they could also be helping them with shopping by providing suggestions and information. From smart marketing to smarter delivery, the future of retail would be dominated by AI as the investment in this space is gradually going up.
The future is definitely going to be impacted by the AI technology in more ways than one. So, be future ready and get yourself upskilled as it is the need of the hour, stay updated and develop the skill to move towards the AI future with confidence.
In my previous blog, I have already introduced you to a statistical term called ANOVA and I have also explained you what one-way ANOVA is? Now in this particular blog I will explain the meaning of two-way ANOVA.
The below image shows few tests to check the relationship/variation among variables or samples. When it comes to research analysis the first thing that we should do is to understand the sample which we have and then try to disintegrate the dataset to form and understand the relationship between two or more variables to derive some kind of conclusion. Once the relation has been established, our job is to test that relationship between variables so that we have a solid evidence for or against them. In case we have to check for variation among different samples, for example if the quality of seed is affecting the productivity we have to test if it is happening by chance or because of some reason. Under these kind of situations one-way ANOVA comes in handy (analysis on the basis of a single factor).
Two-way ANOVA
Two-way ANOVA is used when we are testing the variations among samples on the basis two factors. For example testing variation on the basis of seed quality and fertilizer.
Hopefully you have understood what Two-way ANOVA is. If you need more information, check out the video tutorial attached down the blog. Keep on following the DexLab Analytics blog, to find more information about Data Science, Artificial Intelligence. DexLab Analytics offers data Science certification courses in gurgaon.
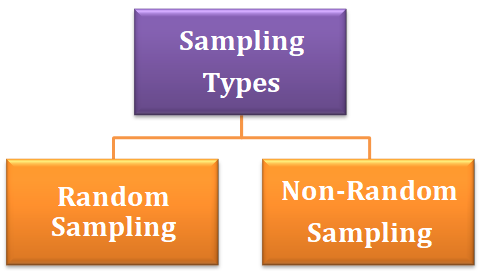
Sampling is a technique in which a predefined number of observation is taken from a large population for the purpose of statistical analysis and research.
There are two types of sampling techniques:-
Random Sampling
Random sampling is a sampling technique in which each observation has an equal probability of being chosen. This kind of sample should be an unbiased representation of the population.
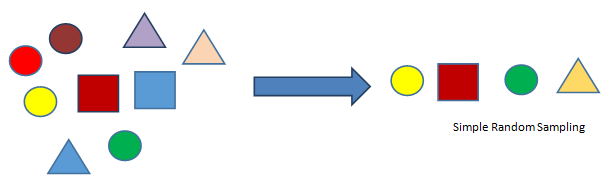
Types of random sampling
Simple Random Sampling:- Simple random sampling is a technique in which any observation can be chosen and each observation has an equal probability of being selected.
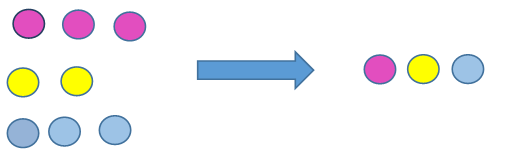
Stratified Random Sampling:- In this sampling technique we create sub-group of the population with similar attributes and characteristics and then out of those sub-groups we then include each category in our sample with the probability of choosing each observation from the sub-group being equal.
Systematic Sampling:- This is a sampling technique where the first observation is selected randomly and then every kth element is chosen randomly to be included in our sample. k= 2, here the first observation is selected randomly and after that every second element is included in the sample.
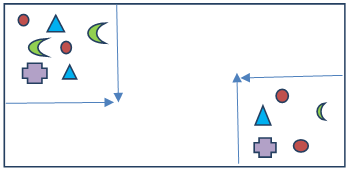
Cluster Sampling:- This is a sampling technique in which the data is grouped into small sub-groups called clusters with random categories and then from those clusters random observation is selected which then is included in the sample.
Two clusters are created from which then random observation will be chosen to form the sample.
Non-Random Sampling :- It is a sampling technique in which an element of biasedness is introduced which means that an observation is selected for the sample on the basis of not probability but choice.
Types of non-random sampling:-
Convenience Sampling:- When a sample observation is drawn from the population based on how comfortable it is for you to take the observation it is called convenience sampling. For example when you have a survey sheet that is to be filled by students from all the departments of your college but you only ask your friends to fill the survey sheet.
Judgment Sampling:– When the sample observation drawn from the population is based on your professional judgment or past experience, it is called judgment sampling.
Quota Sampling:– When you draw a sample observation from the population that is based on some specific attribute, it is called quota sampling. For example, taking sample of people over and above 50 years.
Snow Ball Sampling:– When survey subjects are selected based on referral from other survey respondents, it is called snow ball sampling.
Sampling and Non-sampling errors
Sampling errors:- It occurs when the sample is not representative of the entire population. For example a sample of 10 people with or without COVID-19 cannot tell whether or not the entire population of a country is COVID positive.
Non-sampling error:-This kind of error occurs during data collection. For example, during data collection if you falsely specified a name, it will be considered a non-sampling error.
So, with that this discussion on Sampling wraps up, hopefully, at the end of this you have learned what Sampling is, what are its variations and how do they all work. If you need further clarification, then check out our video tutorial on Sampling attached down the blog. DexLab Analytics provides the best data science course in gurgaon, keep following the blog section to stay updated.
Machine learning has become a popular term as this advanced technology is full of immense potential. Before explaining the intuition behind machine learning let’s understand the meaning of the term first which is becoming so popular in this era of scientific innovation and is a trend that everybody wants to follow.
What is Machine Learning?
Machine learning if explained in a very layman language is a program running behind an application which has an ability to learn from what is sees and the errors that it makes and then tries to improve itself through trial and error. A programming language like Python and a method of calculation (statistics) is what helps propel this application in the right direction.
Now that you know what machine learning is, let’s discuss about what is the intuition behind building a machine learning algorithm or a program.
In my previous blog I have discussed about a statistical concept called Linear Regression which follows given a X independent variable, prediction of a Y dependent variable is possible if we understand the rate at which X and Y are changing and the direction towards which they are moving i.e. we understand the hidden pattern they are following, we will be able to predict the value of Y when X= 15.
In the process of all that, we need to reduce the error between the predicted Y and the observed Y which we had to train our model but this is not possible with only calculating the slope i.e. b1 a single time and this is where machine learning comes in handy.
The idea behind machine learning is to learn from the past mistakes and try to find the best possible coefficients i.e. b0 and b1 so that we are able to reduce the distance between predicted and observed y which leads to the minimization of error in predictions which we are making. This intuition remains the same throughout all the machine learning algorithms only the problem in question and the methodology to solve the problem changes.
Now let’s quickly look at the branches of Machine Learning.
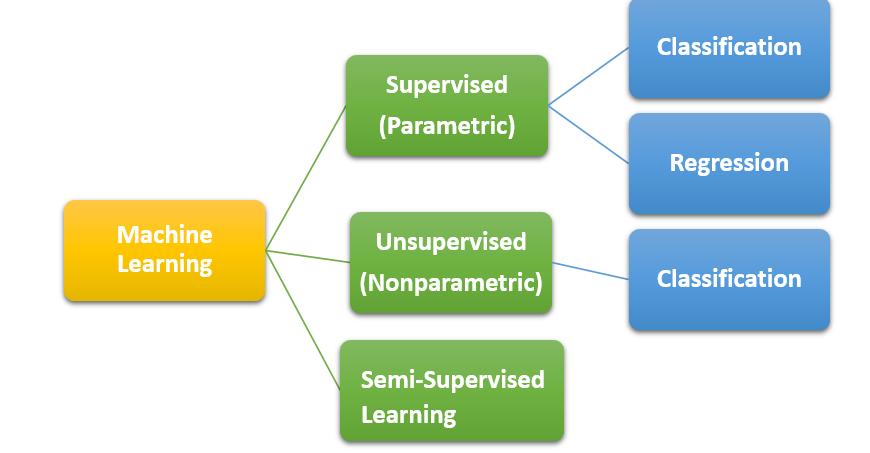
Branches of Machine Learning
Supervised (Parametric) Machine Learning Algorithm:- Under this branch both the independent variable X and the dependent variable Y is given in the form of Y = f(X) and this branch can further be divided based on the kind of problem we are dealing with i.e. whether the variable Y is continuous or a category.
Unsupervised (Non-parametric) Machine Learning Algorithm:- Under this branch you do not have the Y variable i.e. Y ≠ f(X) and you can only solve classification problems.
Semi-Supervised Machine Learning Algorithms:- This is the most difficult to solve as under this kind of problem the data which is available for the analysis has missing values of Y which makes it quite difficult to train the algorithm as the possibility of false prediction is very high.
So, with that this discussion here on machine learning wraps up, hopefully, it helped you understand the intuition behind machine learning, also check out the video tutorial attached down the blog to learn more. The field of machine learning is full of opportunities, DexLab Analytics offers machine learning course in delhi ncr, keep on following the blog to enhance your knowledge as we continue to update it with interesting and informative posts for you.
You must be familiar with the phrase hypothesis testing, but, might not have a very clear notion regarding what hypothesis testing is all about. So, basically the term refers to testing a new theory against an old theory. But, you need to delve deeper to gain in-depth knowledge.
Hypothesis are tentative explanations of a principal operating in nature. Hypothesis testing is a statistical method which helps you prove or disapprove a pre-existing theory.
Hypothesis testing can be done to check whether the average salary of all the employees has increased or not based on the previous year’s data, testing can be done to check if the percentage of passengers increased or not in the business class due to introduction of a new service and testing can also be done to check the differences in the productivity varied land.
There are two key concepts in testing of hypothesis:-
Null Hypothesis:- It means the old theory is correct, nothing new is happening, the system is in control, old standard is correct etc. This is the theory you want to check if is true or not. For example if a ice-cream factory owner says that their ice-cream contains 90% milk, this can be written as:-
Alternative Hypothesis:- It means new theory is correct, something is happening, system is out of control, there are new standards etc. This is the theory you check against the null hypothesis. For example you say that ice-cream does not contain 90% milk, this can be written as:-
Two-tailed, right tailed and left tailed test
Two-tailed test:- When the test can take any value greater or less than 90% in the alternative it is called two-tailed test ( H190%) i.e. you do not care if the alternative is more or less all you want to know is if it is equal to 90% or no.
Right tailed test:-When your test can take any value greater than 90% (H1>90%) in the alternative hypothesis it is called right tailed test.
Left tailed test:-When your test can take any value less than 90% (H1<90%) in the alternative hypothesis it is called left tailed test.
Type I error and Type II error
->When we reject the null hypothesis when it is true we are committing type I error. It is also called significance level.
->When we accept the null hypothesis when it is false we are committing type II error.
Steps involved in hypothesis testing
Build a hypothesis.
Collect data
Select significance level i.e. probability of committing type I error
Select testing method i.e. testing of mean, proportion or variance
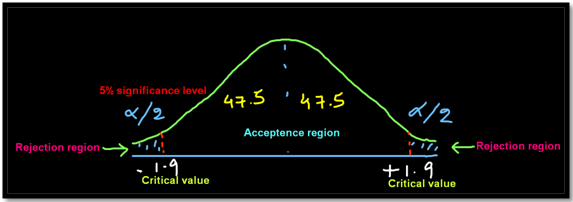
Based on the significance level find the critical value which is nothing but the value which divides the acceptance region from the rejection region
Based on the hypothesis build a two-tailed or one-tailed (right or left) test graph
Apply the statistical formula
Check if the statistical test falls in the acceptance region or the rejection region and then accept or reject the null hypothesis
Example:- Suppose the average annual salary of the employees in a company in 2018 was 74,914. Now you want to check whether the average salary of the employees has increased or not in 2019. So, a sample of 112 people were taken and it was found out that the average annual salary of the employees in 2019 is 78,795. σ=14.530.
We will apply hypothesis testing of mean when known with 5% of significance level.
The test result shows that 2.75 falls beyond the critical value of 1.9 we reject the null hypothesis which basically means that the average salary has increased significantly in 2019 compared to 2018.
So, now that we have reached at the end of the discussion, you must have grasped the fundamentals of hypothesis testing. Check out the video attached below for more information. You can find informative posts on Data Science course, on Dexlab Analytics blog.
Today’s blog explores another vital statistical concept Linear Regression, let’s begin. Linear regression is normally used in statistics for predictive modeling. It tries to model a relationship between two independent (explanatory variable) and dependent (explained variable) variables X and Y by fitting a linear equation (Y=bo+b1X+Ui) to an observed data.
Assumptions of linear regression
Ui is a random real variable, where Ui is the difference between the observed dependent variable Y and predicted Y variable.
The mean of Ui in any particular period is zero.
The variance of Ui is constant in each period i.e for all values of X, Ui will show the same dispersion around their mean
The variable Ui has a normal distribution i.e the value of Ui (for each Xi) have a bell shaped symmetrical distribution about their zero mean.
The random terms of different observations are independent i.e the covariance of any Ui with any other Uj is equal to zero.
Ui is independent of the explanatory variable X.
Xi are a set of fixed values in the hypothesised process of repeated sampling which underlies the linear regression model.
In case there are more than one explanatory variables then they are not perfectly linearly correlated.
Linear Regression equation can be written as:
Where,
is the dependent variable
X is the independent variable.
b0 is the intercept (where the line crosses the vertical y-axis)
b1 is the slope
Ui is the error term (difference between ) also called residual or white noise.
Simple linear regression follows the properties of Ordinary Least Square (OLS) which are as follows:-
Unbiased estimator:- E()=b ie. an estimator is unbiased if its bias is 0; E() – b = 0
Minimum Variance:- An estimate is best when it has the smallest variance as compared to any other estimate obtained from other econometric method.
Efficient estimator:- When it has both the previous properties ie.
Linear estimator
Best, Linear, Unbiased estimator (BLUE)
Minimum mean squared error (MSE) estimator:- It is a combination of the unbiasedness and minimum variance properties. An estimator is a minimum MSE estimator if it has the smallest mean square error.
With that the discussion on Linear Regression wraps up here, hopefully it cleared away any confusion you might have and helped you get a grasp on the concept. We have a video discussion on this same topic, which is attached below this blog, check it out for further reference.
If you are aware of the growth opportunities awaiting you in the Machine Learning domain, you must be in a rush to master the Machine Learning skills. Now, there are courses available that aim to sharpen the students with skills they would need to work in a challenging environment. However, some often prefer the self-study mode for developing knowledge in this highly specialized domain. No matter which way you prefer to learn, ultimately your passion and dedication would matter the most, because in both ways you need to put in the hard work and really toil hard to make any progress.
Is self-study a feasible option?
If you have already been through some course and want to go to the advanced level through self-study that’s a different issue, but, for those who are just starting out without any background in science, does it even make any sense to opt for self-study?
Given the way Machine Learning technology is moving fast and creating a demand for professionals with highly specialized industry knowledge, do you think self-study would be enough? Do you think a self-study plan to learn something you have no idea about would work? How much time would you need to devote? What should be your learning route? And how do you know this is the right path to follow?
Before we dive deeper into the discussion, we need to go through some prerequisites for Machine Learning study plan.
Machine learning is a broad field and assuming you are a beginner with no prior knowledge in this domain, you have to be familiar with mathematics, statistics, programming languages, meaning undergoing a Python certification training</strong>, must be proficient in data handling including analysis and modeling, you have to work on algorithms. So, can you pick up all of these skills one by one via self-study? Add to the list the latest Machine Learning tools and applications you need to grasp.
There will be help available in the form of:
There would be vast resources, in forms of e-books, lectures, video tutorials, most of these are free and easily accessible.
There are forums, groups out there which you can join and access help
You can take part in online competitions
Think it through. How long will it take for you to get from one stage to the next?
Even though there being no dearth of resources available you would be struggling with your progress and most importantly you would struggle to keep up with the pace the technology is moving ahead. Picking up a programming language, grasping and mastering concepts of linear algebra, probability, data is going to be a mammoth task.
What difference a certification course can make?
To begin with these courses are designed for people coming from different backgrounds, so, you having or, not having any prior knowledge in mathematics, statistics wouldn’t matter as you would be taught everything from scratch be it math or, Machine Learning Using Python.
The programs are designed for both working professionals as well as for beginners, all you need to do is choose the one that suits your specific level.
These courses are designed to transform you into an industry-ready professional and you would be under the guidance of professionals who are more than familiar with the nuances of the way the industry functions.
The modules would follow a strict schedule and your training path would be well planned out covering all the areas you need to master.
You would learn via hands-on training and get to handle projects. Nothing makes you skilled like hands-on training.
Your journey towards a smarter future needs to be through a well mapped-out path, so, be smart about it. DexLab Analytics offers industry-ready courses on Data Science, Machine Learning course in Gurgaon and AI with Python. Take advantage of the courses that are taught by instructors who have both expertise and experience. Time is indeed money, so, stop wasting time and get down to learning.

 We can use .array() methods to create these arrays.
We can use .array() methods to create these arrays.