Our industry experts introduce beginners to Machine Learning Algorithms with Python. In this blog, we will go through various Machine Learning Algorithms to understand the concepts better. This is the first part of a series.
Machine Learning, a subset of Artificial Intelligence, is a process of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that computing systems can learn from data, identify patterns in them and make intelligent decisions with minimal human intervention.
Parametric and Non-Parametric ML Algorithms
We first divide the mathematical methods for decision making in to sections – parametric and non-parametric algorithms. Parametric has a functional form while non-parametric has no functional form.
Functional form comprises a simple formula like 2+2=4 or Y=F(X). So if you input a value, you are to get a fixed output value. That means, if the data set is changed or being changed, there is not much variation in the results. But in non-parametric algorithms, a small change in data sets can result in a large change in the results.
But we do not desire this. We do not want this massive change in results in investments, for instance. We have various ways to solve this difficulty. For example, in statistics, you must have learnt the Central Limit Theorem – As the number of samples increase, the data will start following the normal distribution.
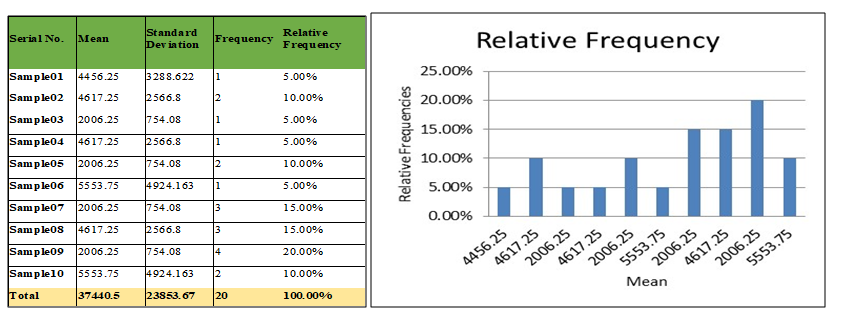
Here is an experiment on decision making with the help of non-parametric algorithm. We first take a random sample, and we apply an algorithm to it to get a result. We repeat this process several times and get an average of the results. In this way, the variation in our results goes down considerably. We will get a central tendency.
Take for example stock market data where prices are totally random. There is no fixed pattern to it. It is a manmade phenomenon. In the same way, we can make predictions in data sets only when there is a particular pattern. It becomes that much more difficult to make predictions in the absence of a clear pattern. In such a case, we take thousands of samples and work them to get a result before investing. We can use a Decision Tree like Random Forest for this.

Supervised and Unsupervised Algorithms
Now, secondly, we can term ML algorithms as supervised or unsupervised algorithms. Suppose we have data under sub-heads – Name, Age, Gender and Salary and Period of Service. Now, consider the model wherein we are asked to predict the period of service of an employee based on data provided under the rest of the sub-heads based on existing employee data.
Now, in this example, the period of service is the Target. The data sets on the basis of which the prediction will be made – Name, Age, Gender, Salary – is the Input. In such a model, where the target variable is specified, we term it as supervised machine learning algorithm. We do this according to a formula – Y=B0 + B1X1.
In unsupervised learning, the target variable is not provided and all we can do is divide the historical data in clusters. For example, Google Translate runs on a supervised model as do chatbots. Data is not only the new oil, it is everything. And there will come a time of data colonisation whereby the organisation with the best data will rule. The better the date, the better our ML models. Who has the best data sets in the world? Google and Amazon, among others, do.
So this is it, about supervised and unsupervised machine learning. For more on this, do watch our intensive video tutorial on ML algorithms.
(Translated till first 28:00 minutes)
This is the first blog of the series, stay tuned with Dexlab Analytics to read through the whole video we’ll covering in our upcoming blogs!
.